Man kann jetzt über DHCPv4 mehrere Nameserver announcen. Das ist konfiguierbar und es gibt zwei Typen: Alle anderen Gateways der Domäne als Nameserver und zusätzliche Namensserver (z. B. „externe“), die in den host_vars/group_vars in einer Liste angegeben werden:
Wenn die dhclients
auch so implementiert haben, sollte immer der Namensserver bevorzugt werden, von dem das DHCP Lease ausgestellt wurde.
Ich habe das auf remue-09 und des2 ausgerollt und ein stichprobenartiger Test verlief einwandfrei. Als zusätzliche (externe) Namensserver habe ich den vom FoeBud/Digitalcourage und den vom CCC in Berlin gesetzt.
Da Remue-09 die IP’s für Dom01 ausgegangen sind um ca 9.00 Uhr den Tunneldigger auf Remue-09 neu gestartet um einige Knoten aus Domäne 01 zu Des2 zu schubsen…
Der geplante reboot auf remue-09 heute Nacht war leider nicht erfolgreich (hing beim herunterfahren, hat nicht alle interfaces runter bekommen). Vorhin daher per Hand neu gestartet und ein paar l2tp verbindungen drauf geworfen.
Die Tunneldigger-Rolle insoweit angepasst, dass sie entweder, wie bisher, als eine Instanz für alle Domänen laufen kann oder mit einer Instanz je Domäne. Die gewünschte Konfiguration kann mittels Variable definiert werden. Außerdem können nun einige weitere Einstellungen über Variablen konfiguriert werden.
Collectd auf Parad0x ist nach dem geplanten Neustart nicht wieder hoch gekommen.
–> Collectd restartet. --> tut wieder…
Apr 09 09:42:47 parad0x collectd[8303]: Unhandled python exception in read callback: OperationalError: FATAL: the database system is starting up
FATAL: the database system is starting up
Apr 09 09:42:47 parad0x collectd[8303]: Traceback (most recent call last):
Apr 09 09:42:47 parad0x collectd[8303]: File "/opt/collectd-python/kea.py", line 15, in read
active_leases = performPSQL()
Apr 09 09:42:47 parad0x collectd[8303]: File "/opt/collectd-python/kea.py", line 6, in performPSQL
conn = psycopg2.connect("host='127.0.0.1' dbname='kea_leases' user='##########' password='####################'")
Apr 09 09:42:47 parad0x collectd[8303]: File "/usr/lib/python2.7/dist-packages/psycopg2/__init__.py", line 164, in connect
conn = _connect(dsn, connection_factory=connection_factory, async=async)
Apr 09 09:42:47 parad0x collectd[8303]: OperationalError: FATAL: the database system is starting up
FATAL: the database system is starting up
Das gilt es herauszufinden. Augenscheinlich scheint es aber auch nicht schlechter zu laufen. Da ich herausfinden wollte, wie gut die Verteilung der Knoten auf die unterschiedlichen Gateways klappt (uns ich im Zweifel das ganze per Knopfdruck innerhalb weniger Minuten wieder auf den vorherigen Zustand zurücksetzen lässt), habe ich das Ganze auf alle Gateways ausgerollt, die gemeinsame Domänen haben. Daher habe ich des1 und parad0x auch außen vor gelassen.
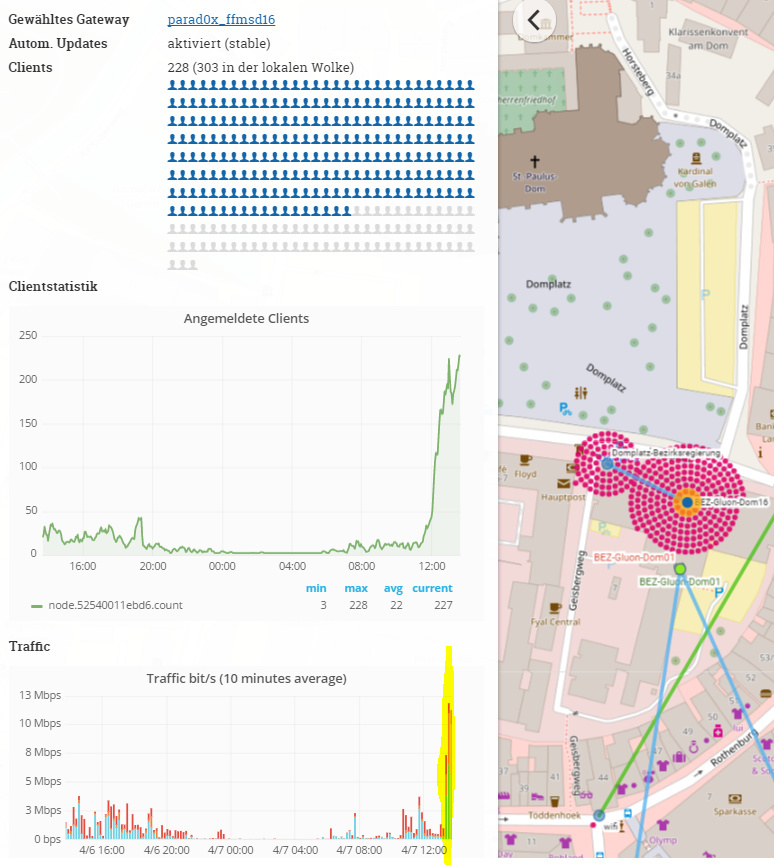
Am Domplatz hat die 5GHz Nanostation mal wieder keine Clients angenommen.
Daher reboot der 5GHz Nanostation am Domplatz. Ich habe den Zeitpunk ganz unten gelb markiert. Man sieht schön, dass es etwas gebracht hat
Ich habe eine neue Gruppe “RebootDaily4am” angelegt und entsprechend konfiguriert. Die beiden APs vom Domplatz werden jetzt über den AirControl täglich um 4 Uhr neu gestartet. Damit hat sich das Problem hoffentlich erledigt.
Rollen für Installation eines LAMP Stacks sowie das einrichten von osTicket gebaut.
Im gleichen Atemzug Rollen gebaut um Backups mittels Borg Backup einzurichten.
Mangels Backupziel / Konzept sichert das Ticketsystem aktuell auf meinen Server und auf eine Scaleway Kiste auf die das @Adminteam zugriff hat. Die Keys für die Backup Repos werden von Ansible unter ansible-ffms/keyfiles/borg/<quellhost>-to-<zielhost>.repokey gespeichert und mittels .gitignore Eintrag wird verhindert das diese bei GitHub landen. Dafür sollten wir uns etwas überlegen wie und wo wir diese noch sichern wollen. Die Rollen sind so gebaut das sie auf allen Systemen von uns laufen sollten. Der Grundstein für unser Backup ist also gelegt.
Wenn Interesse besteht wie die Rollen angewendet werden kann ich darüber gern mal an einem Mittwoch in der WZ was erzählen. Ich hab mir aber vorgenommen noch README’s zu schreiben!!11elf!
Den Docker-Container vom alten Ticketsystem auf dem Webserver habe ich gestoppt und einen rewrite für /helpdesk zur neuen URL in die nginx config eingetragen. Siehe auch: