Die Tunneldigger-Rolle insoweit angepasst, dass sie entweder, wie bisher, als eine Instanz für alle Domänen laufen kann oder mit einer Instanz je Domäne. Die gewünschte Konfiguration kann mittels Variable definiert werden. Außerdem können nun einige weitere Einstellungen über Variablen konfiguriert werden.
Webserver nach Ausfall durch Upgrade repariert
2 „Gefällt mir“
Collectd auf Parad0x ist nach dem geplanten Neustart nicht wieder hoch gekommen.
–> Collectd restartet. --> tut wieder…
Apr 09 09:42:47 parad0x collectd[8303]: Unhandled python exception in read callback: OperationalError: FATAL: the database system is starting up
FATAL: the database system is starting up
Apr 09 09:42:47 parad0x collectd[8303]: Traceback (most recent call last):
Apr 09 09:42:47 parad0x collectd[8303]: File "/opt/collectd-python/kea.py", line 15, in read
active_leases = performPSQL()
Apr 09 09:42:47 parad0x collectd[8303]: File "/opt/collectd-python/kea.py", line 6, in performPSQL
conn = psycopg2.connect("host='127.0.0.1' dbname='kea_leases' user='##########' password='####################'")
Apr 09 09:42:47 parad0x collectd[8303]: File "/usr/lib/python2.7/dist-packages/psycopg2/__init__.py", line 164, in connect
conn = _connect(dsn, connection_factory=connection_factory, async=async)
Apr 09 09:42:47 parad0x collectd[8303]: OperationalError: FATAL: the database system is starting up
FATAL: the database system is starting up
1 „Gefällt mir“
MultiTD auch auf remue-08 ausgerollt.
Wollen wir Parad0x auch aus den automatischen Neustarts rausnehmen?
Nö. Das schöne an den regelmäßigen reboots ist ja, dass uns alles recht schnell auf die Füße fällt, was nicht korrekt konfiguriert ist.
Korrekte frage wäre also: Wollen wir schauen, warum der collectd auf parad0x nicht hoch gekommen ist?
Deaktivieren würde ich das nur, wenn sich jemand bereit erklärt dort regelmäßig von Hand upgrades einzuspielen und zu rebooten.
1 „Gefällt mir“
MultiTD ist jetzt auf allen VMs außer auf des1 und parad0x ausgerollt.
Für @corny456 eine VM für das Ticketsystem auf deshyper-01 konfiguriert.
Wissen wir denn schon, dass das besser läuft?
Das gilt es herauszufinden. Augenscheinlich scheint es aber auch nicht schlechter zu laufen. Da ich herausfinden wollte, wie gut die Verteilung der Knoten auf die unterschiedlichen Gateways klappt (uns ich im Zweifel das ganze per Knopfdruck innerhalb weniger Minuten wieder auf den vorherigen Zustand zurücksetzen lässt), habe ich das Ganze auf alle Gateways ausgerollt, die gemeinsame Domänen haben. Daher habe ich des1 und parad0x auch außen vor gelassen.
Bis jetzt sieht aber alles recht gut aus.
Ah okay, ergibt Sinn mit der Verteilung und kann auch eigentlich nur besser werden. 
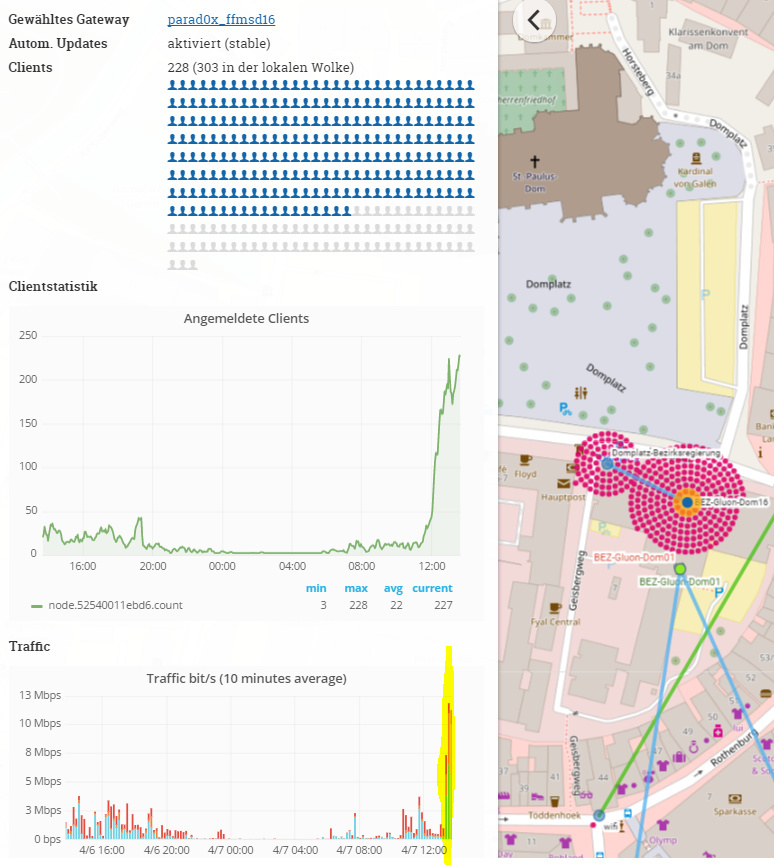
Am Domplatz hat die 5GHz Nanostation mal wieder keine Clients angenommen.
Daher reboot der 5GHz Nanostation am Domplatz. Ich habe den Zeitpunk ganz unten gelb markiert. Man sieht schön, dass es etwas gebracht hat 
Ich habe eine neue Gruppe “RebootDaily4am” angelegt und entsprechend konfiguriert. Die beiden APs vom Domplatz werden jetzt über den AirControl täglich um 4 Uhr neu gestartet. Damit hat sich das Problem hoffentlich erledigt.
1 „Gefällt mir“
Forum aktualisiert.
4 „Gefällt mir“
Rollen für Installation eines LAMP Stacks sowie das einrichten von osTicket gebaut.
Im gleichen Atemzug Rollen gebaut um Backups mittels Borg Backup einzurichten.
Mangels Backupziel / Konzept sichert das Ticketsystem aktuell auf meinen Server und auf eine Scaleway Kiste auf die das @Adminteam zugriff hat. Die Keys für die Backup Repos werden von Ansible unter ansible-ffms/keyfiles/borg/<quellhost>-to-<zielhost>.repokey gespeichert und mittels .gitignore Eintrag wird verhindert das diese bei GitHub landen. Dafür sollten wir uns etwas überlegen wie und wo wir diese noch sichern wollen. Die Rollen sind so gebaut das sie auf allen Systemen von uns laufen sollten. Der Grundstein für unser Backup ist also gelegt. ![]()
Wenn Interesse besteht wie die Rollen angewendet werden kann ich darüber gern mal an einem Mittwoch in der WZ was erzählen. Ich hab mir aber vorgenommen noch README’s zu schreiben!!11elf!
Den Docker-Container vom alten Ticketsystem auf dem Webserver habe ich gestoppt und einen rewrite für /helpdesk zur neuen URL in die nginx config eingetragen. Siehe auch:
3 „Gefällt mir“
Nach Aufstand den “Whos Online” aus dem Forum entfernt. Dabei die Installation vom Forum zerlegt und wieder zusammengefügt.
5 „Gefällt mir“
HipChat aktualisiert wg
https://confluence.atlassian.com/hc/hipchat-server-security-advisory-2017-04-12-887732597.html
2 „Gefällt mir“
Do, 16:32 CEST: in den letzte 24h keinen Server geschrottet.
In diesem Sinne: Frohe Ostern!
7 „Gefällt mir“
Node-Stats auf das neue™ System umgestellt. Läuft noch nicht perfekt, aber die Übergangslösung ist geplatzt (Speicher voll) und daher habe ich es schon mal umgestellt. Liegt zum großen Teil schon in ansible. Ausführlicher Bericht folgt, muss jetzt mal dringend ne Runde schlafen 
5 „Gefällt mir“
Kernel & Userland vom Wiki aktualisiert.
Geht noch
2 „Gefällt mir“
“interfaces-rollen” auf remue-09 ausgerollt. Sieht so aus, als ob der reboot jetzt wieder funktioniert. Keine der Änderungen hat mich aber direkt angesprungen und gesagt “ich war der Schuldige”, daher müssen wir noch mal etwas Zeit abwarten und schauen, ob es dann immer noch funktioniert.
Hintergrund: Remue-09 hing beim reboot bzw. network restart, da es ein interface nicht abgerissen bekommen hat.
1 „Gefällt mir“