Ich fände einen Ansatz, der die Form algorithmisch bestimmt attraktiv.
Das ganze sieht wie eine überschaubare Optimierungsaufgabe auf.
Erster Schritt wäre wohl eine Bewertungsfunktion zu bestimmen. D.h. wann ist eine Aufteilung “gut”?
Das wäre auch ohne automatisches Shaping vielleicht eine lohnenswerte Diskussion
Willst du in den Algorithmus nur Knotendaten werfen? Oder auch rudimentäre topographische Informationen? Wie sieht es mit Mesh-Links aus?
Wenn man das nur auf basis der knotenpositionen löst, besteht die Gefahr, dass dann ungewöhnliche Grenzen, z. B. quer durch ein Wohngebiet bekommt.
Wenn wir das algorithmisch bestimmen, würde ich aber auch dieses ganze Auswähl-Foo, sowie die drei trillionen Firmware-Varianten wegwerfen und das so machen, wie die NWler das machen: Mehr oder weniger „automatisch“ die richtige Domäne/GWs auf den Knoten wählen.
Vielleicht kann man ja irgendwie auf das grundlegende Konzept der SVMs aufbauen, die haben ja auch zum Ziel (im n-dimensionalen Raum) „Punktwolken“ möglichst optimal zu trennen.
Vielleicht geht man das Problem auch anders herum an: Man baut Domänenkandidaten aus Landmarks: Flächen, die durch Bundesstraßen/Autobahnen, Flüsse, Administrative Grenzen (>= definierter Level) und Bahntrassen abgegrenzt werden (mehrere Gleise bzw. mehrere Spuren müssten natürlich gemerged werden, etc.) . Und darüber lässt man dann eine Bewertungsfunktion laufen, wie gut die für eine Domäne geeignet sind. Damit sprengt man vermutlich nicht so schnell die Komplexitätsklasse.
Also man hat quasi dann (n-eckige) Tiles. Benachbarte Tiles fügt man so lange zusammen, bis das Ergebnis gut ist.
@kgbvax für das clustern scheint k-means ein probates Mittel zu sein. Das bekommt man durch scipy in python geschenkt. Für QGIS gibt es dort auch (mindestens) zwei Möglichkeiten: Attribute based clustering (dort habe ich xcoord und ycoord testweise mal als attribute rein geworfen), welches sich aber bei mir bei mehr als einem Attribut irgendwie auf die Nase gelegt hat, bzw. unerwartete Ausgaben produzierte. Sowie das Concave Hull Plugin, welches die Funktion “Shared Nearest Neighbor Clustering” mit bringt. Die allerdings dann nur auf Basis der Koordinaten clustern kann. Hier muss man allerdings recht viel mit dem “kernel parameter” k spielen.
Nun denn, dann sollten wir wieder zurück zu deiner anfänglichen Frage und klären, welche Features wir definieren wollen.
Wir haben ja knotenspezifische Features, die wir dann in den k-means werfen wollen. Aber wir haben ja auch Anforderungen an das Ergebnis, z. B. als Domänengröße. Diese können wir nutzen, um iterativ die Gewichte der einzelnen Features anzupassen, bis das Ergebnis optimal wird.
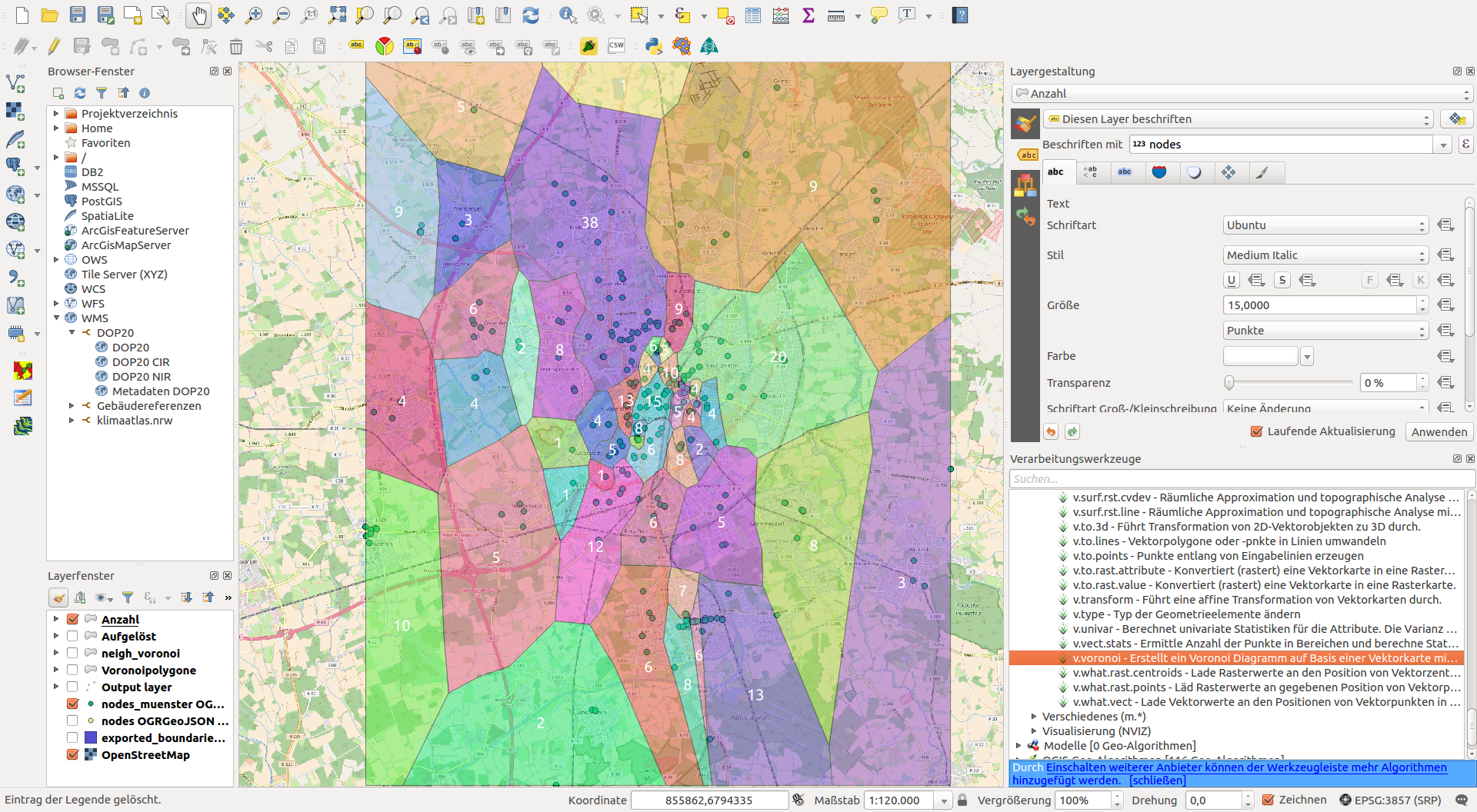
Ich hätte an dieser Stelle noch die Idee, die Aufteilung in verschiedene, gleich große Bereiche über ein Voronoi-Diagramm zu erledigen. Ein passendes Verfahren müsste man™ sich aber noch überlegen.
Ein Voronoi-Diagramm habe ich bei mir als einen eher nachgelagerten Schritt verwendet, da die Anforderung war aneinander grenzende Polygone zu bekommen, schieden Hüllen (concav oder convex) aus.
Mein Vorgehen:
k-means mit recht kleinem cluster (k) Parameter → ergebnis als attribut „class“ an die punkte geschrieben
Voronoi-Diagramm erstellen, um aus der Punktwolke aneinander grenzende Polygone zu erhalten (class attribut wurde auf die polygone übertragen)
Die Anzahl der Knoten innerhalb eines Polygons/Klasse wird durch die entsprechende Zahl repräsentiert.
Mein nächster Schritt wäre jetzt benachbarte Polygone solange zusammenzufügen, bis die Anzahl der Knoten im gewünschten Bereich liegt.
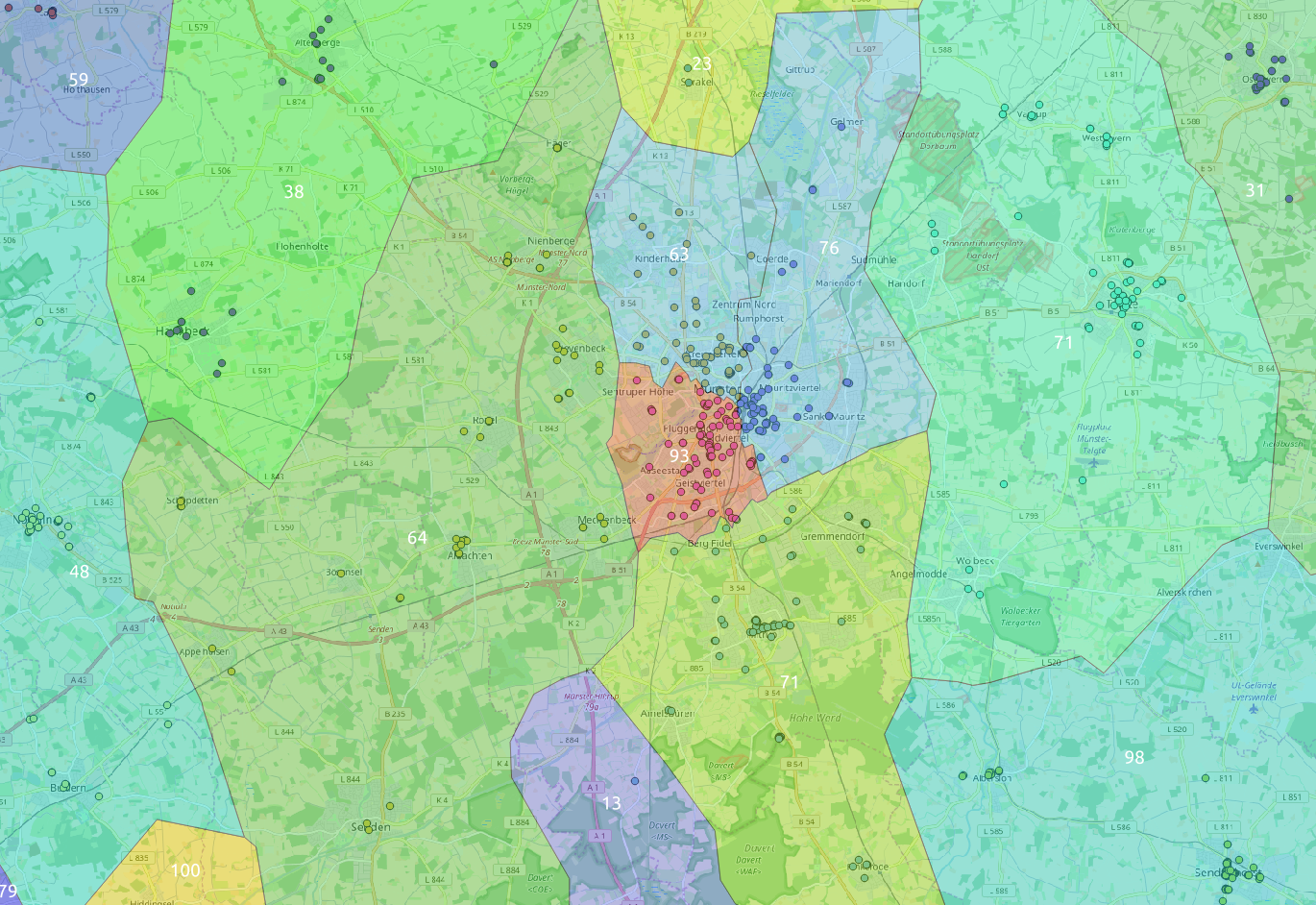
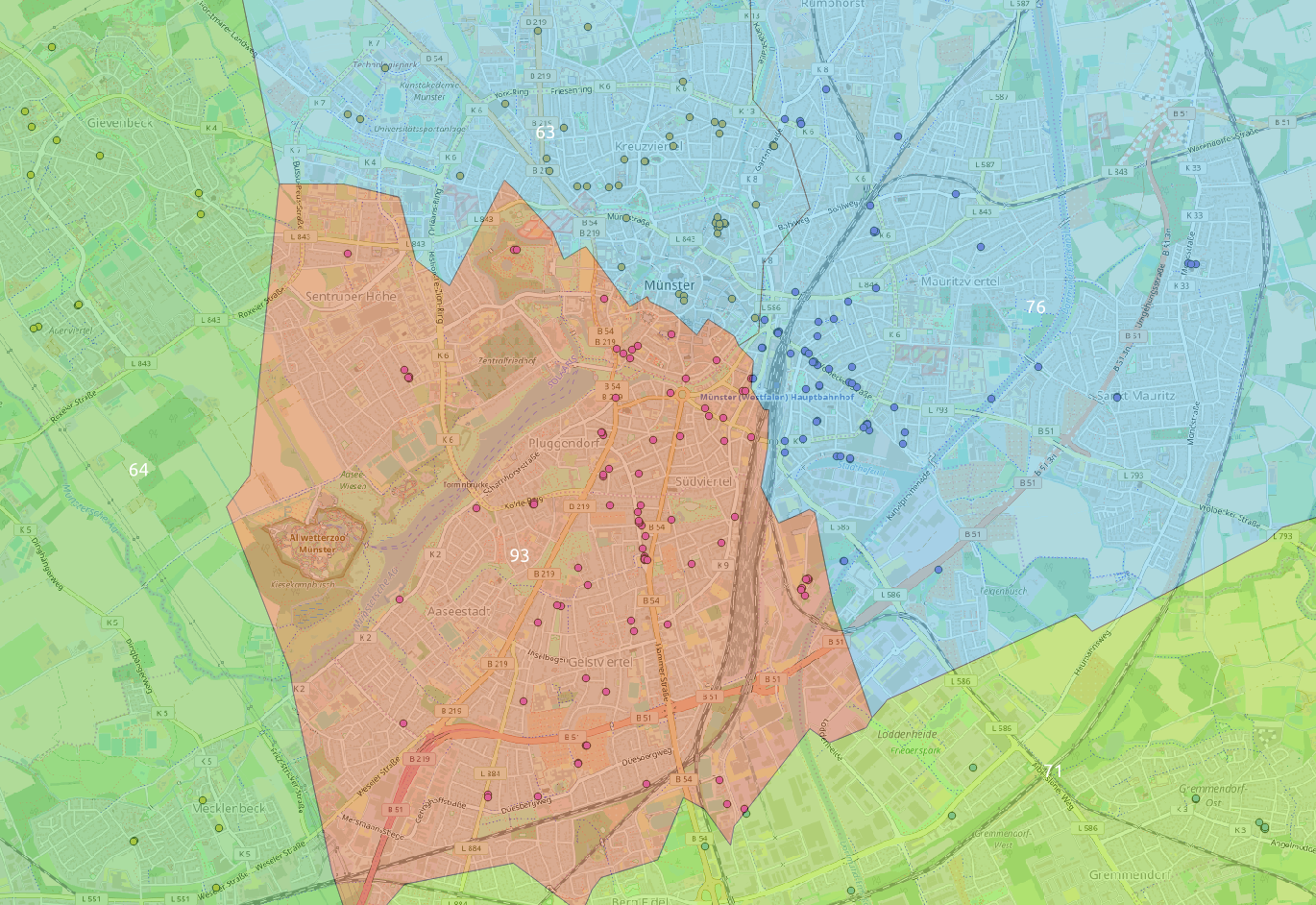
Mit einem Blick auf Hiltrup wird aber klar, dass das zusammenfügen von benachbarten polygonen nur auf basis eines attributs (anzahl knoten) problematisch werden könnte.
Ich werde mir dennoch mal die dichtebasierenden Ansätze anschauen. Ich werde aber auch noch mal meine Unterlagen zur Computer Vision Vorlesung durchschauen, hier scheint es eine recht große Schnittmenge (außer halt die Verfahren für Rasterdaten) zu geben.
Edit:
Ein anderer Anssatz wäre direkt mit Polygonen zu starten: Man nimmt die Informationen über Mesh-Links hinzu und wirft dann über die daraus enstehende lokale Wolke eine Hülle.
Danach könnte man iterativ vorgehen:
Erstelle/Vergrößere Buffer
Füge überlappende Polygone zusammen
Berechne Anzahl an Knoten innerhalb
Liegt Anzahl Knoten im Zielbereich → Entferne Polygon aus dem Prozess & speichere in separat als potentielle Domäne
Ist Anzahl Knoten > Zielbereich → wähle größtes (nach Anzahl Knoten in Polygon) der betreffenden Polygone aus Schritt i-1 und entferne dieses
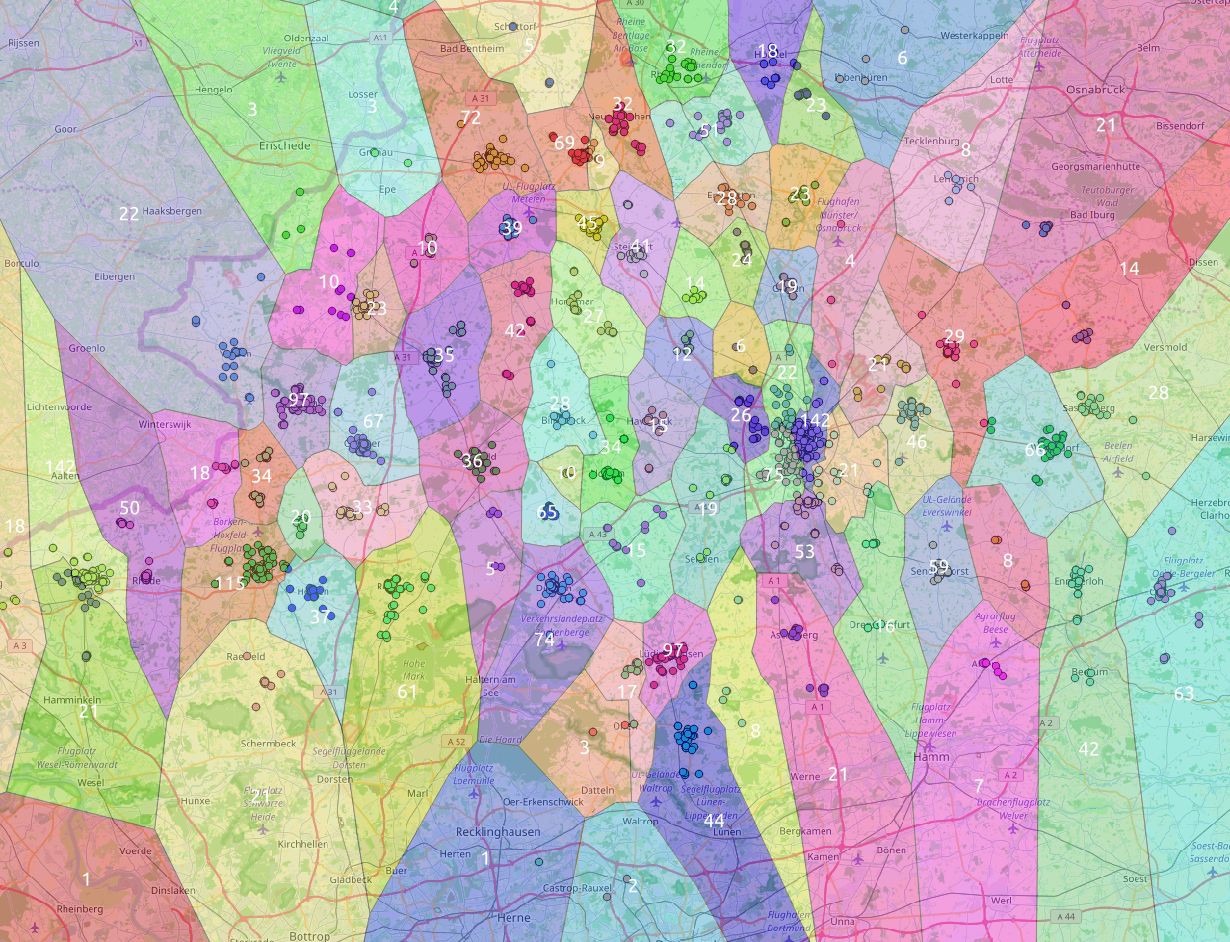
Ich habe jetzt mal den k-means von openCV genutzt, also in Python. Der ist sehr viel mehr konfigurierbar. So habe ich auch cv2.KMEANS_PP_CENTERS anstatt cv2.KMEANS_RANDOM_CENTERS verwendet. Außerdem ist das teil signifikant schneller als das Teil in QGIS. Die “veredelung”, also Voronoi, malen, zahlen habe ich dann wieder mit QGIS gemacht.
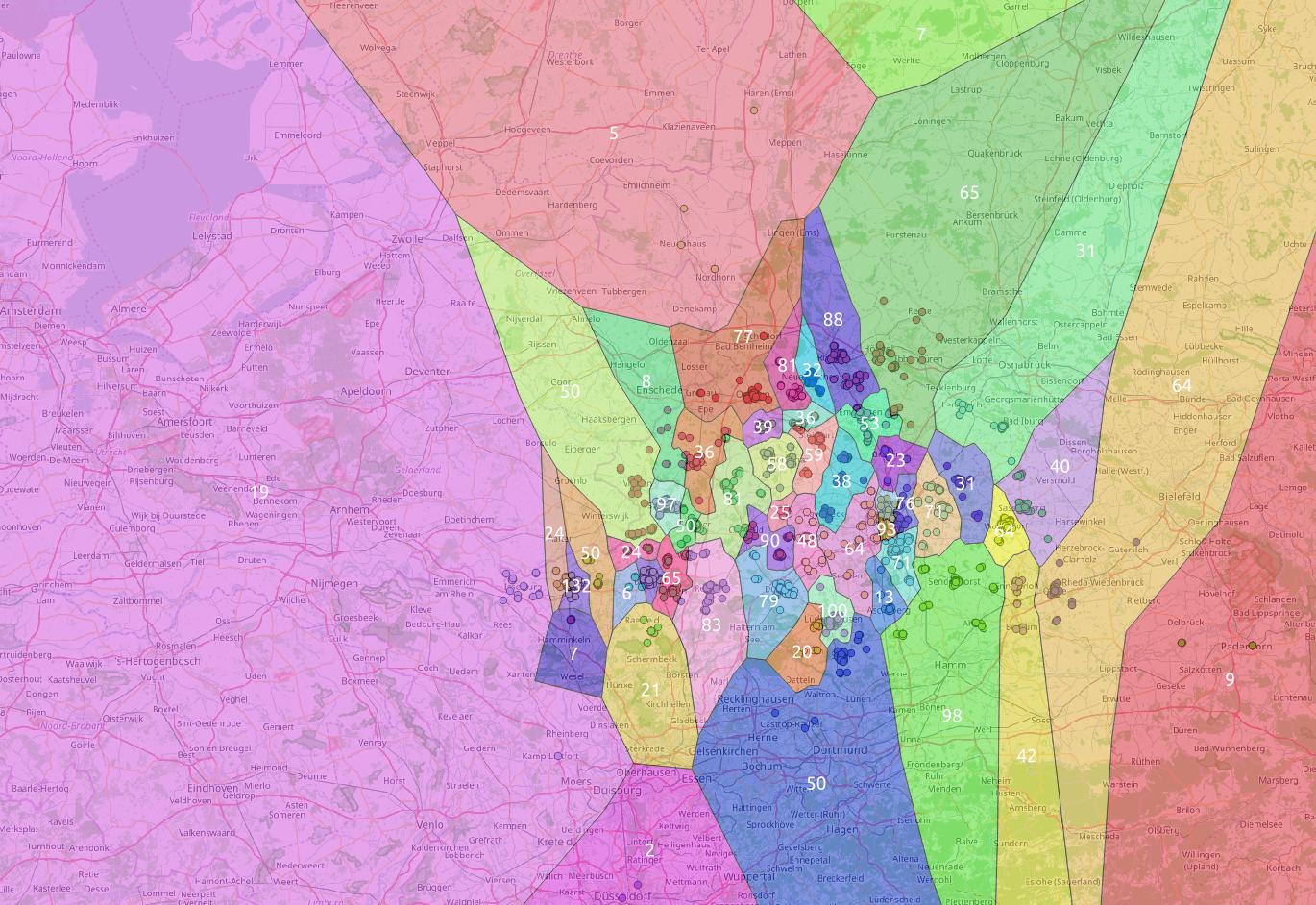
Ein erster Versuch mit #clusters = 100 habe ich dann auch gleich mal auf alle Knoten los gelassen:
Imho ist das Ergebnis für den Anfang echt nicht schlecht. Und das nur auf Basis der Koordinaten als Features-Vektor.
Ich denke wir haben nun einen Punkt erreicht, an dem wir die prinzipielle Machbarkeit gezeigt haben. Wir sollten nun klären ob und wie wir so etwas nutzen wollen.
PS: Hier findet sich die Übersichtsseite von openCV bzgl. Machine Learning:
Ein Tipp: Verwende eine Projektion zum Clustern und auch für die Voronoi-Diagramme, die in beiden Achsen die gleiche Skalierung verwendet (z. B. EPSG:3857).
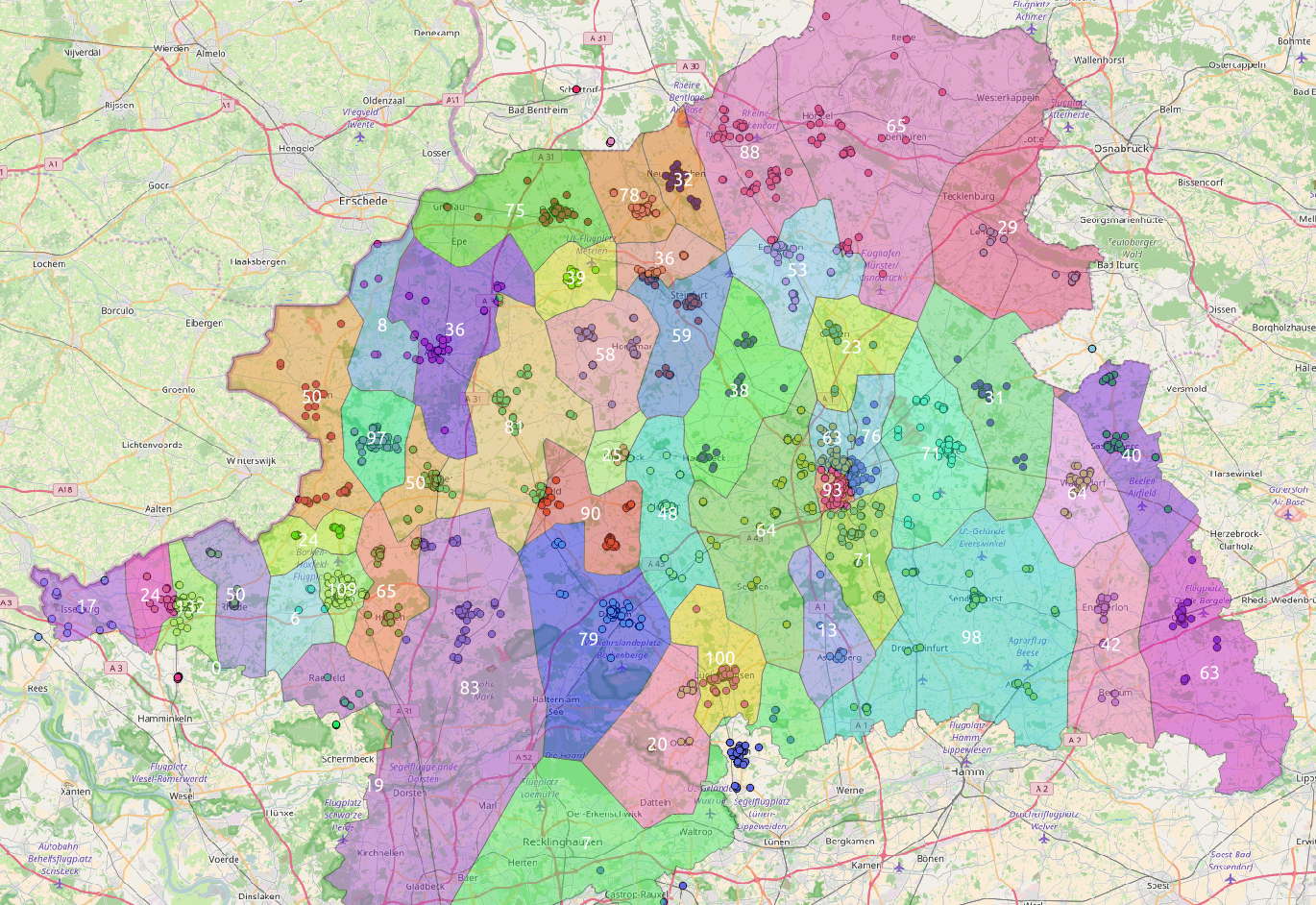
Das bisherige Problem war, dass bei einer zu kleinen Anzahl an Clustern die Cluster in den Städten viel zu groß (Anzahl Knoten) und bei einer zu großen Anzahl an Clustern die Cluster in weniger besiedelten Regionen viel zu klein (Anzahl Knoten) wurden.
Daher gehe ich jetzt rekursiv vor: Ich gebe zunächst eine eine moderate Anzahl an Clustern vor. Danach prüfe ich, ob es Cluster gibt, die einen vorgegebenen Schwellenwert überschreiten. Auf diese Cluster (also nicht mehr global) führe ich dann einen erneuten k-means Durchlauf durch mit kluster-anzahl := ceil(knoten-anzahl/schwellenwert). Dieses wird solange durchgeführt, bis alle Cluster den vorgegebenen Schwellenwert unterschreiten.
Edit: Der kmeans von openCV gibt einen “compactness” wert zurück. Diesen könnte man ebenfalls als Entscheidungskriterien für weitere Iterationen heranziehen.
Außerdem sollte man den Features-Vektor um einen Wert erweitern, der vermeidet, dass sehr nahe Knoten unterschiedlichen Clustern zugeordnet werden.
PS: Innerhalb des Bezirksregierung-Münster Shapes wären das sogar nur 50 Domänen.