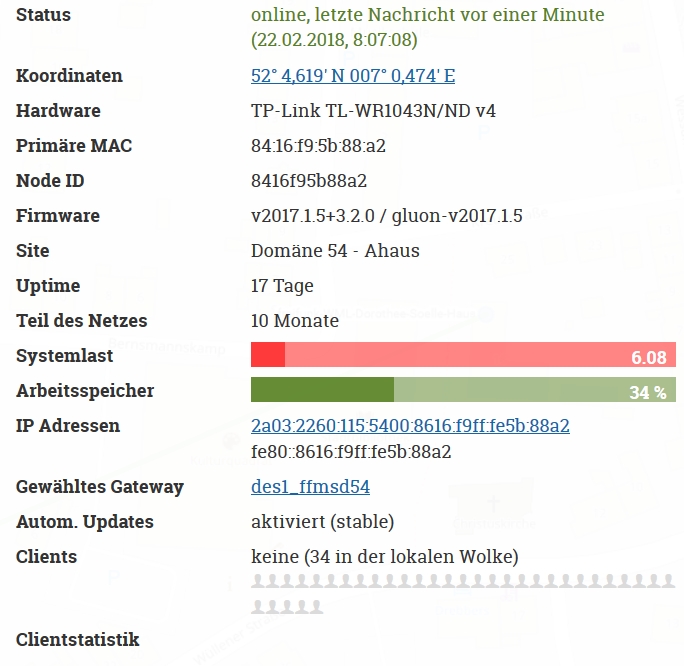
Ich hab ehrlich gesagt den Tunneldigger in Kombination mit den schwachen 32/4 Geräten im Verdacht.
Wenn ich bei mir VPN durch einen 1043er machen lasse und den 841er, der vorher die Auslastungsprobleme hatte, nur im Mesch mitlaufen lasse, tritt der Bug nicht auf.
@corny456, wir könnten mal den alten FFRL-Tunneldigger in die Firmware bauen und gucken, ob die auch auf den schwachen Kisten stabil läuft.
Bevor ich den Knoten boote:
kann ich aus dem laufenden System noch hilfreiche Daten/Infos/Logs extrahieren, die der Usachenforschung dienlich sein könnten?
Edit:
Das Ding hat sich inzwischen selbst wieder gefangen. Was könnte ich beim nächsten Vorfall abfragen?
Also das Problem ist wohl, dass man das auf den 4 MB-Geräten nicht diagnostizieren kann, weil man perf nicht draufkriegt. Ich hab es nicht mehr genau im Kopf, aber ich meine, die Gluon-Entwickler hätten letztens gesagt, dass das auf den 8 MB-Flash-Geräten nicht viel anders ist, weil dem Kernel da einfach die Diagnoseschnittstellen fehlen.
Glaub wir müssen da evtl. doch nochmal ein separates Issue bei Gluon zu aufmachen, weil der Fehler bei uns anders auftritt als in anderen Freifunkgruppen.
Im IRC kam noch eine weitere Debugmöglichkeit auf: Selektiv mittels ebtables Traffic abdrehen und gucken, wann die Auslastung sinkt. Dann könnte man das etwas eingrenzen.
<T_X> hexa-: wenn ihr demnächst nochmal so einen knoten mit hoher load und auch mit ssh zugang habt, könntet ihr einfach mal solange in die "ebtables -t nat PREROUTING" chain solange regeln zum droppen dazu packen, bis die load runter geht?
<hexa-> ^ blocktrron
<hexa-> ja, kriegen wir vermutlich hin
<hexa-> also einfach mal mit sowas wie arp anfangen?
<T_X> genau
<T_X> hier und da einfach mal traffic wegschnippeln. wenn ARP nicht hilft, dann ip4, dann ip6 usw. wenn ip4 zu helfen scheint, dann z.B. icmpv4 wegschneiden. oder auch einfach mal per bitmaske die hälfte aller MAC source-adressen wegfiltern
<hexa-> öh ja, bitmaske … klar x)
<T_X> also ebtables manpage hat ja da so einen eintrag zu "-s, --source [!] address[/mask]"
<hexa-> yep, sehe ich
<T_X> "-s 00:00:00:00:00:00/01:00:00:00:00:00" -> alles unicast. "00:00:00:00:00:00/01:00:00:00:00:01" würde dann schonmal alle mac-adressen wegfiltern, die als letztes bit eine 0 haben
<hexa-> hm ja, da fehlt mir ein wenig wissen wie mac addressen aufgebaut sind
<T_X> oder in vier unicast ranges geteilt: 00:00:00:00:00:00/01:00:00:00:00:03, 00:00:00:00:00:01/01:00:00:00:00:03, 00:00:00:00:00:02/01:00:00:00:00:03, 00:00:00:00:00:03/01:00:00:00:00:03
<T_X> hexa-: ne, das hat damit nix zu tun. hat was mit manpage lesen und verstehen zu tun ;)
<hexa-> buuuh :D
<hexa-> Unicast=00:00:00:00:00:00/01:00:00:00:00:00, Multicast=01:00:00:00:00:00/01:00:00:00:00:00, Broadcast=ff:ff:ff:ff:ff:ff/ff:ff:ff:ff:ff:ff
<hexa-> ja, gefunden :p
<T_X> sorry, nicht böse gemeint :P
<hexa-> nicht böse angekomen :)
<hexa-> ich weiss mit mühe und not, dass die 33er macs für multicast sind
<T_X> aber so ein vierteln des traffics wie oben genannt könnte auch schon interessant sein
<hexa-> oder so(TM)
<T_X> wenn das problem tatsächlich von einem bestimmten gerät ausgehen sollte, könnte man's mit dem vierteln nach source adressen evtl. schon festtstellen
<T_X> ach ja, und auchwenn ihr alles in der PREROUTING komplett filtert und die load trotzdem noch hoch bleibt, wäre das natürlich äuch interessant zu wissen (sollte man vll. sogar zu erst probieren)
<T_X> alle mac addressen, die _1:, _3:, _5:, ..., _F: haben, sind multicast
<T_X> _0:, _2:, ..., _E: sind unicast
<hexa-> https://md.darmstadt.ccc.de/ffda-ranz-debug# notiert :p
<T_X> (genauer, das erste bit im ersten byte der MAC 0 -> unicast. erstes bit im ersten byte 1: multicast)
<hexa-> top
<hexa-> also ungerade zweite stelle :D
<hexa-> ^ multicast
<T_X> aber ja, 33:33: wird z.B. von ipv6 für multicast benutzt
<T_X> denn _3: hat ja auch das 1. bit im 1. byte auf 0
<T_X> öh, erste stelle, nicht zweite? oder du meinst gerade zweite stelle in der ascii-hex-schreibweise. dann stimmt's wieder :D
<hexa-> jo :D
<T_X> immer verwirrend, dieses bitweise gefummel...
Wir haben gestern abend den Batman Multicast Modus abgeschaltet. Danach haben sich einige Knoten mit 3.2.0 nich wieder verbunden. Wir wissen noch nicht genau warum. Boot tut gut… Danach gehts wieder…
Ich habe hier auf zwei Geräten mit 3.2.0er-Firmware mal testweise das Mesh-Netz abgeschaltet. Ein wifi reload führt dazu, dass iw anscheinend hängen bleibt:
root@ffwaf-[.....]:~# ps | grep iw
17031 root 1076 D iw dev mesh0 del
Jetzt ohne auf die genaue Domäne drauf schauen zu können tippe ich mal, dass die Version noch nicht signiert ist. Die Router nehmen das Update erst wenn:
ein entsprechend passender Link gesetzt ist
das manifest, in diesem Fall für experimental, von mindestens 1 Person signiert worden ist
Vorher muss erstmal per Hand das update gemacht werden.
Wenn du nicht dringend das update brauchst, ruhig so lassen. Wir brauchen auch Router, die den Autoupdater-Prozess im experimentellen Stadium durchlaufen. Dann ist auch das getestet.